Create, Teach, and Tune ML Transform
1. Create FindMatches ML Transform
1a) Navigate to AWS Glue Console -> On the left side, under ETL -> Jobs -> ML Transforms
1b) Click on Add Transform
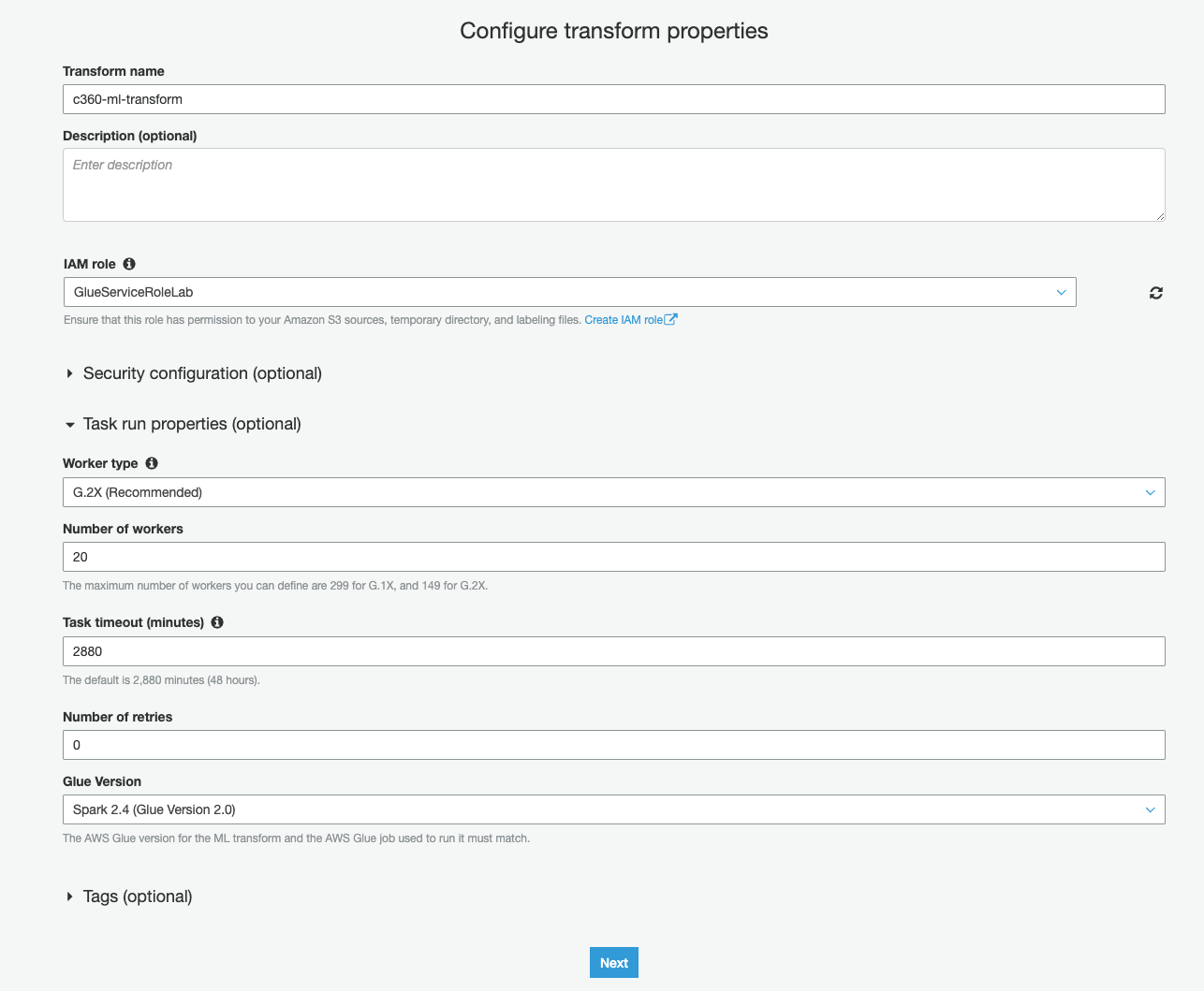
1c) Specify c360-ml-transform as Transform name
1d) IAM Role containing tag “GlueServiceRoleLab”
1e) Expand Task Run Properties section
1f) Select Worker Type as G.2X (Recommended)
1g) Enter Number of Workers as 20
1h) Glue Version as Spark 2.4 (Glue Version 2.0)
1i) Keep other values as default and click on Next
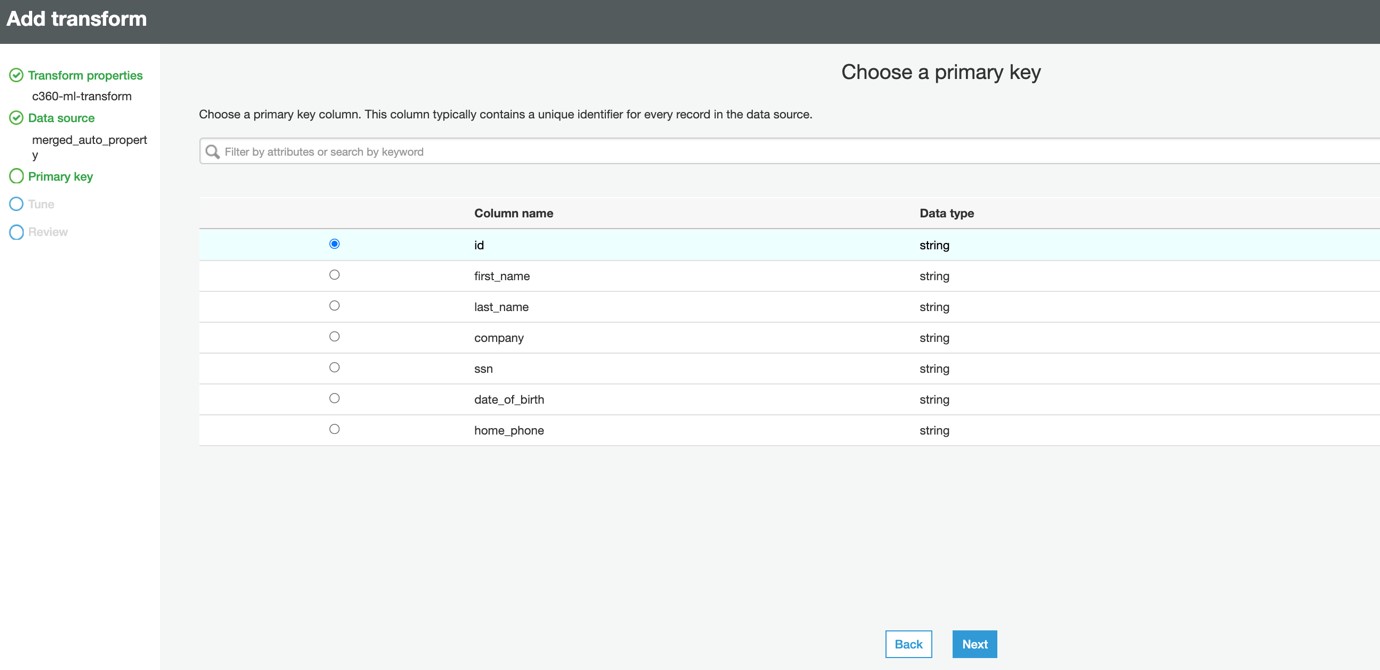
1j) Select merged_auto_property as a Data Source and click Next

1k) Select id as a primary key in the next page
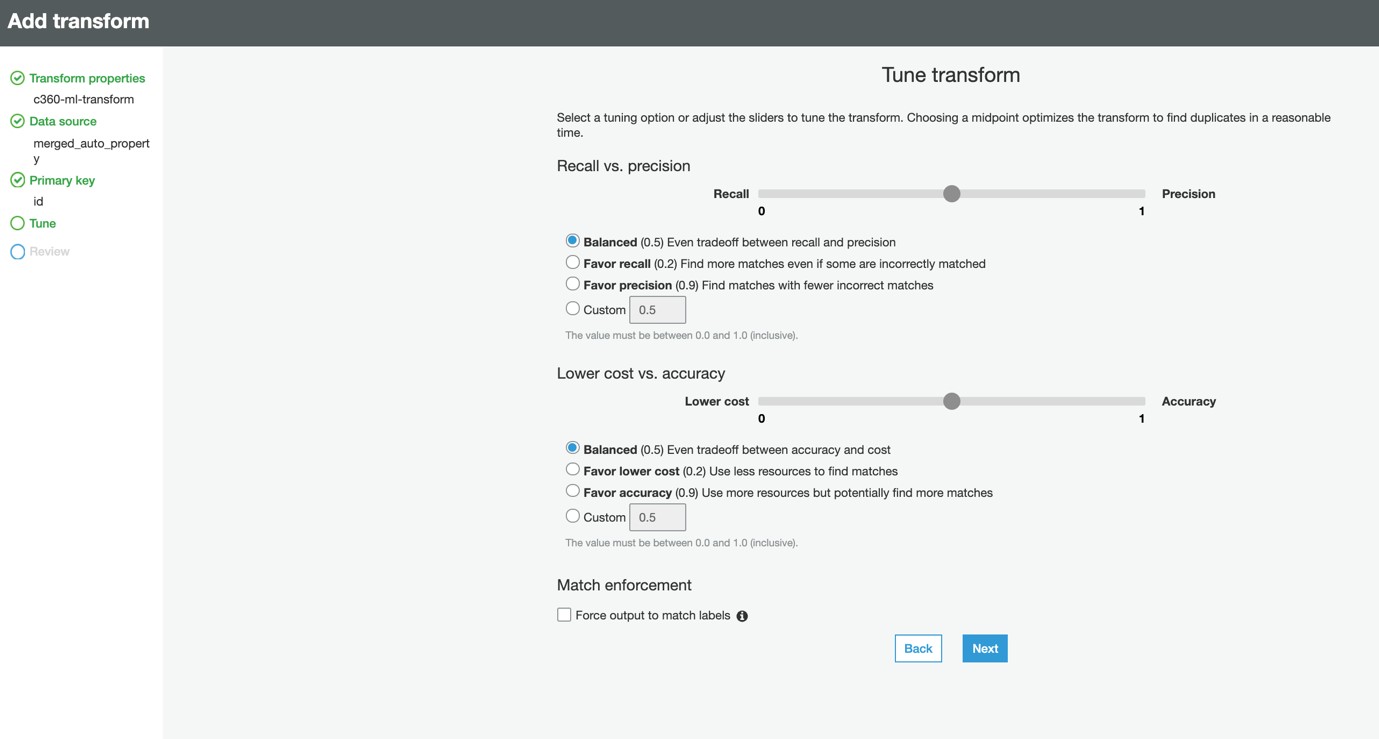
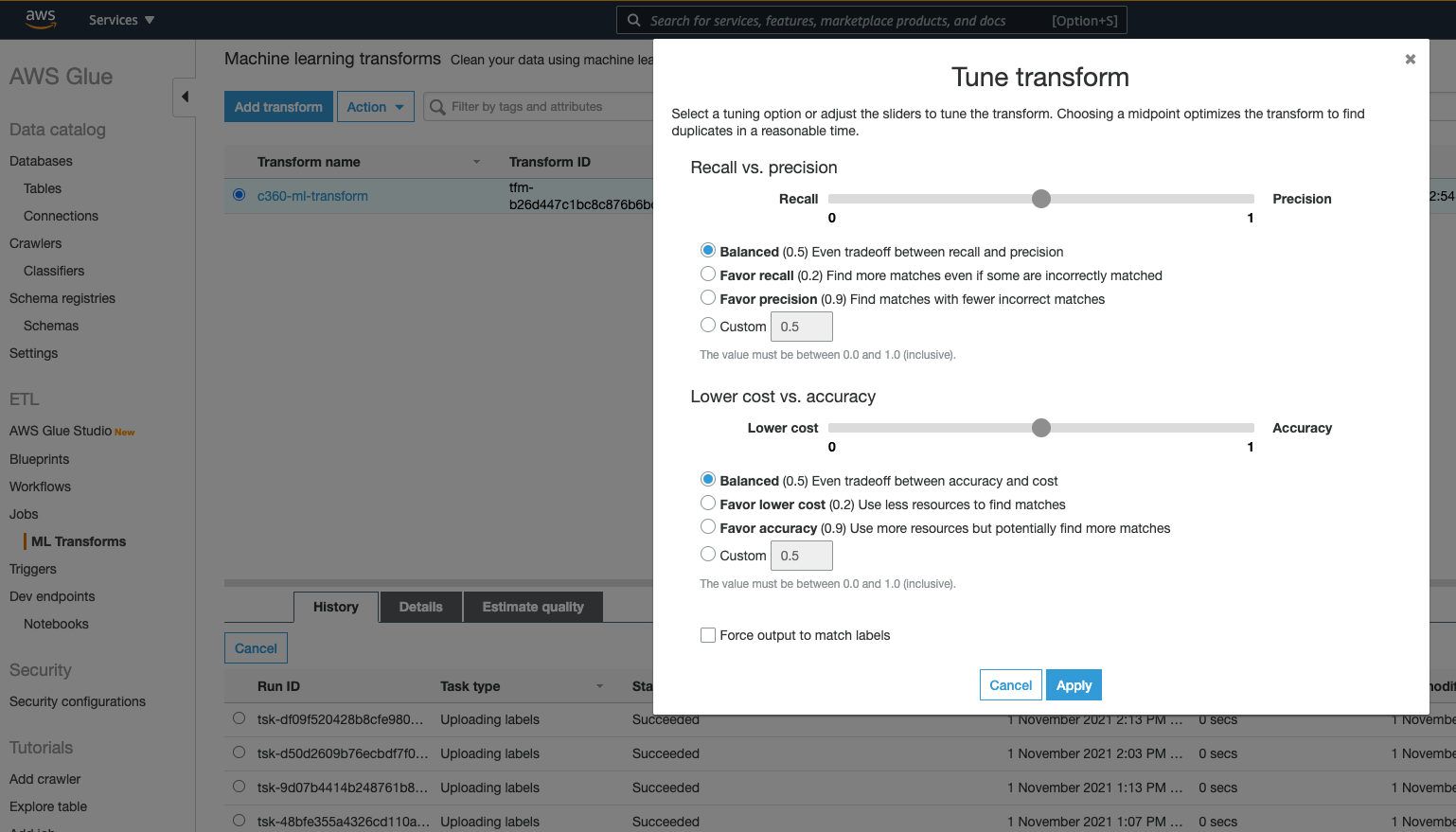
1l) In the Tune Transform step, you can tune performance and cost metrics available for ML Transform. We will stay with default tradeoffs for a balanced approach.
We have specified these values to achieve balanced results. If needed, you can later tweak these values by selecting the transform and using the Tune menu.
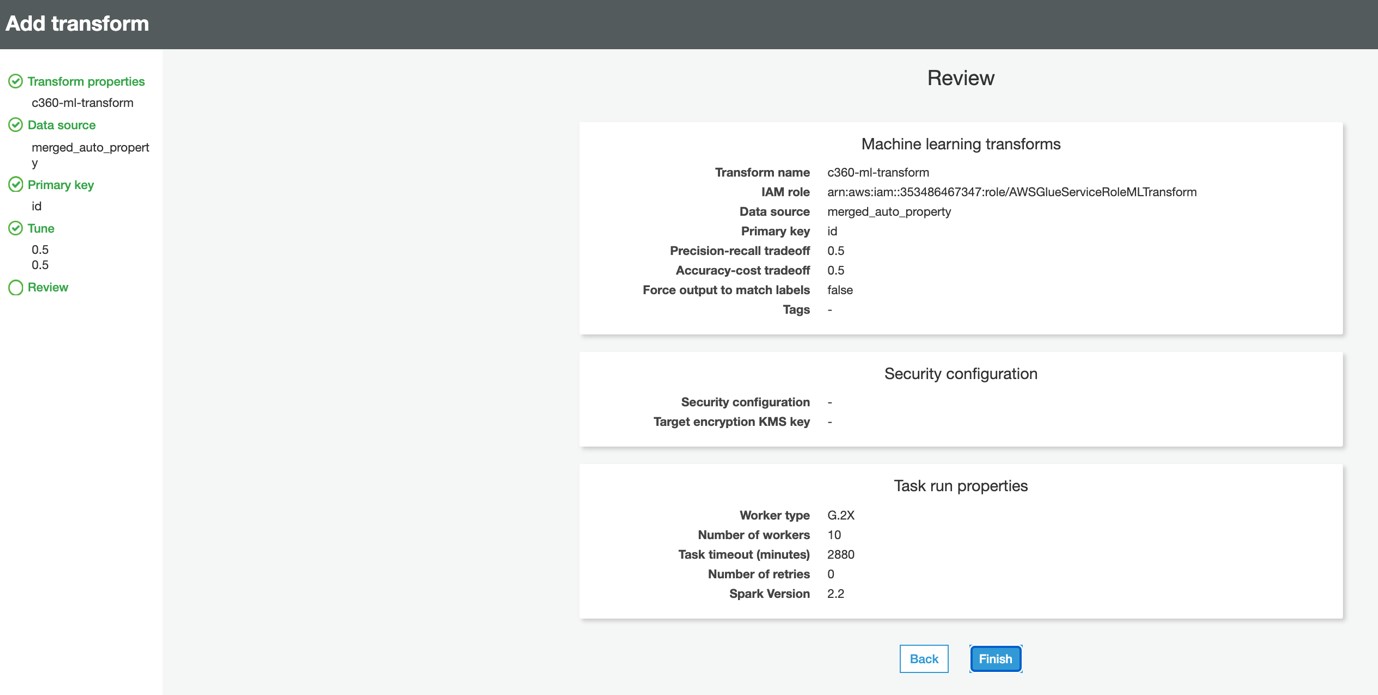
1m) Review the values and click Finish
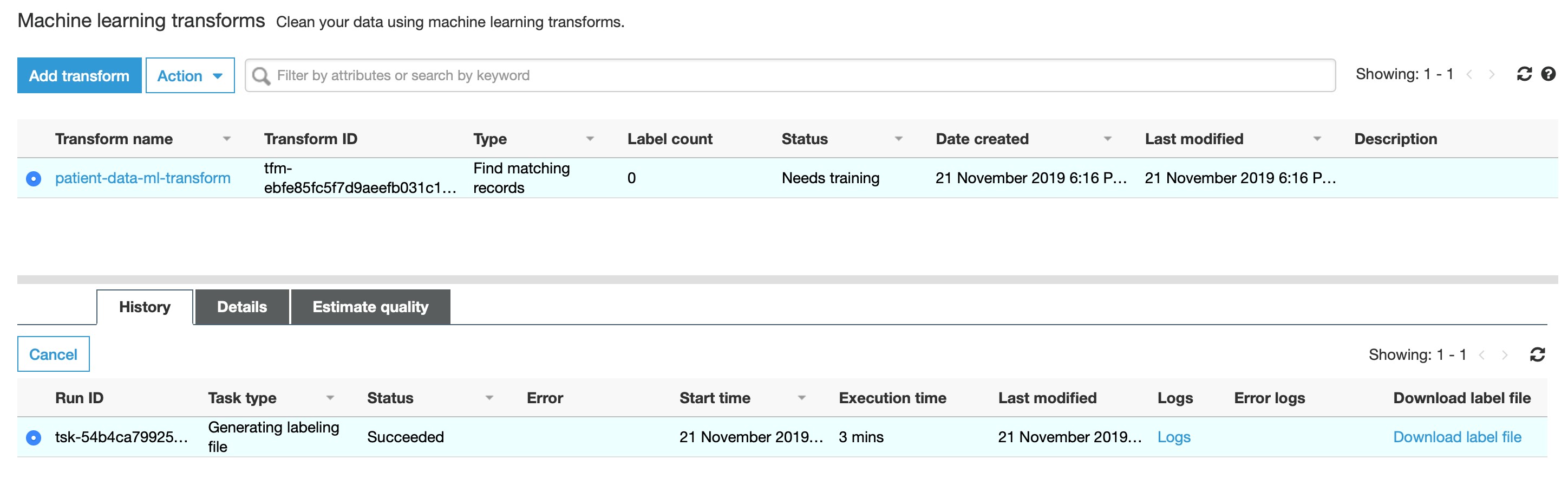
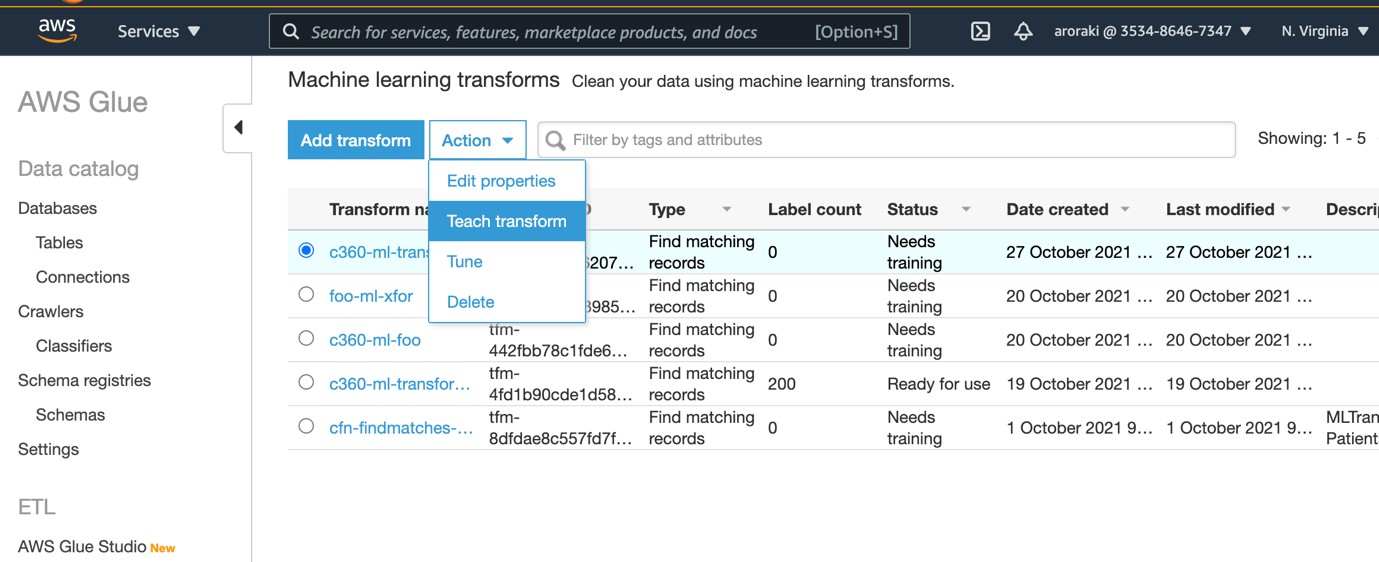
The ML transform is created with Status Needs training

2. Teach transform to identify the duplicates
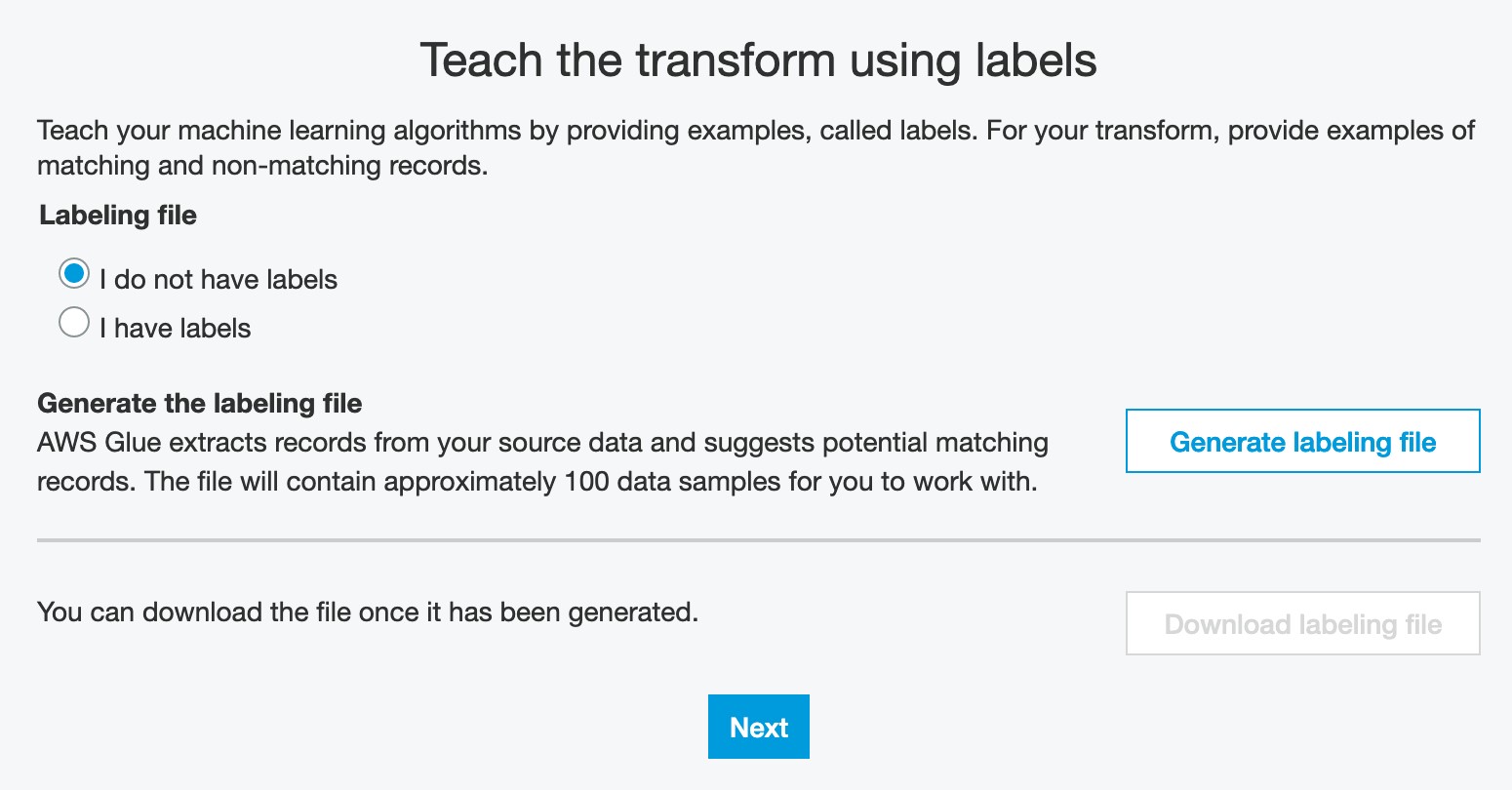
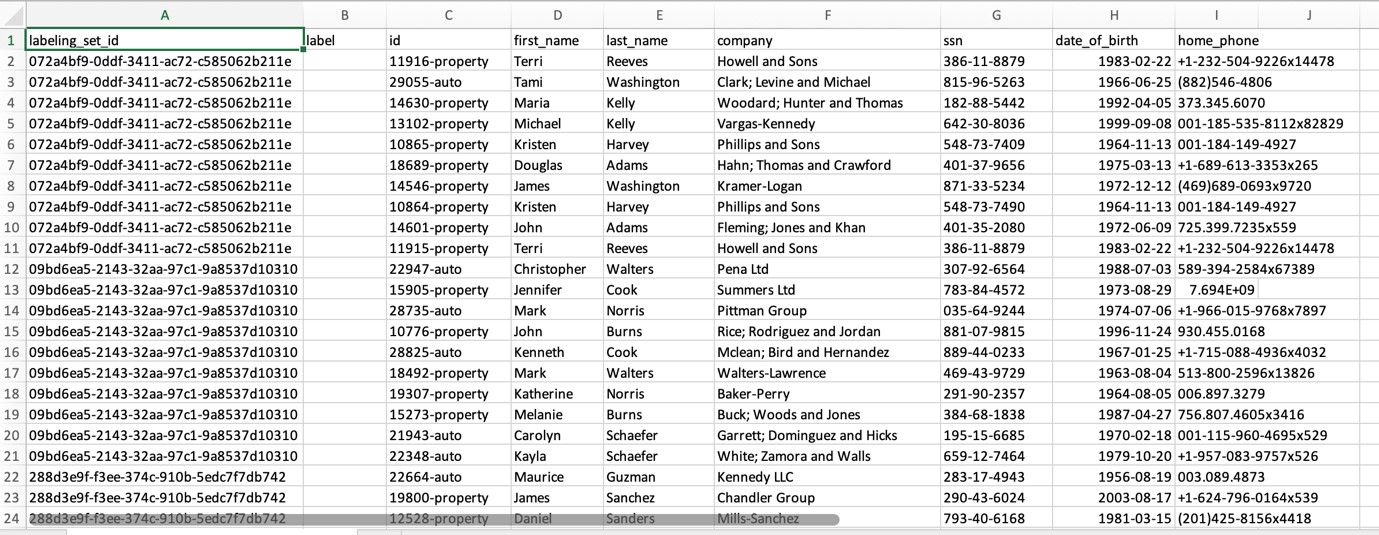
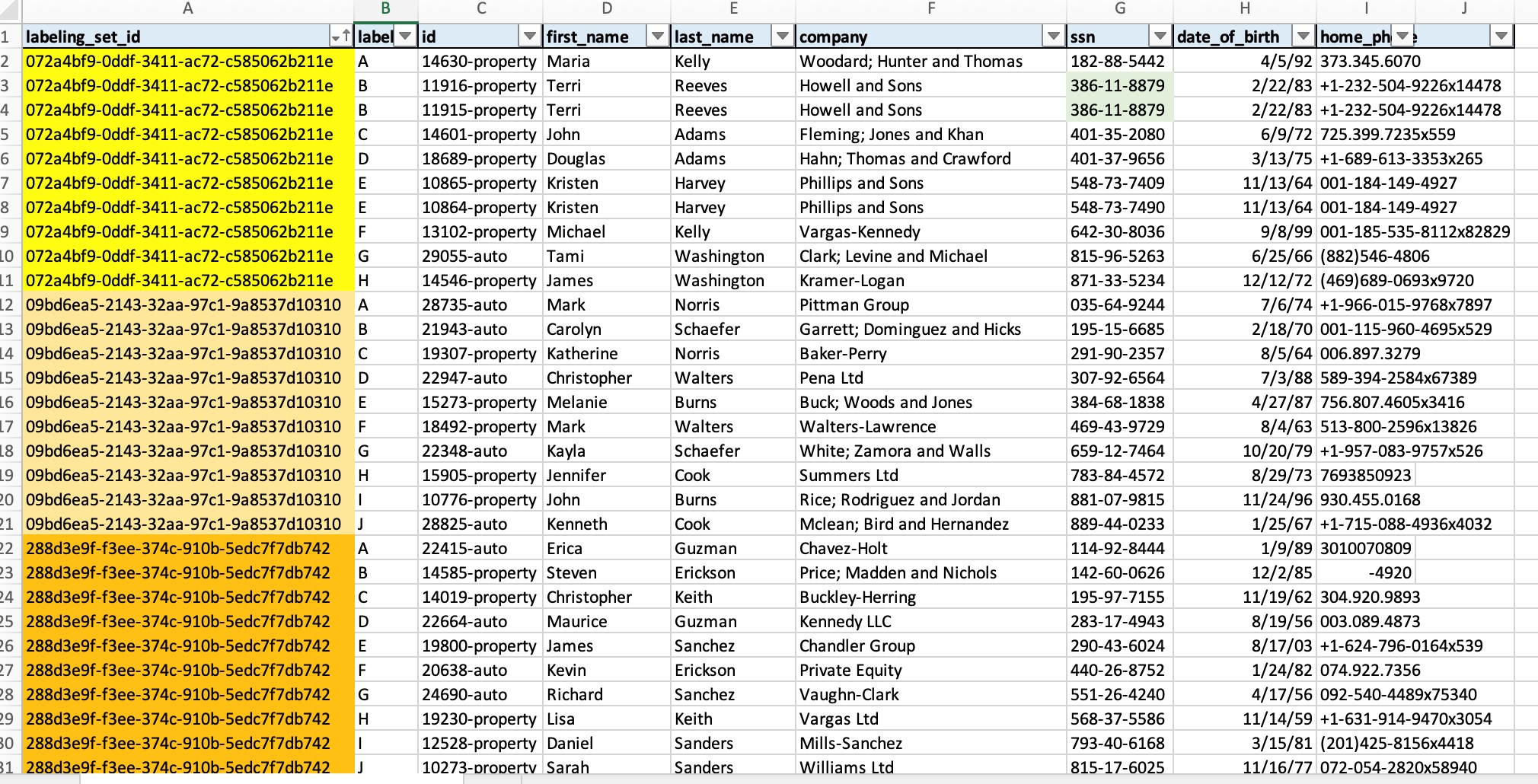
In this step we will teach the transform by providing labelled examples of matching and non-matching records. You can create your labeling set yourself or allow AWS Glue to generate the labeling set based on heuristics. AWS Glue extracts records from your source data and suggests potential matching records. The file will contain approximately 100 data samples for you to work with.
Note We recommend using the “Generate the Labeling file” feature to create the initial training set to teach your Transform for your fuzzy matching use-cases. Please refer to the APPENDIX at the end of this Lab on how to generate labels using ML Transform and prepare them for teaching it. In this lab, we will use pre-created labeled files in the interest of time.
2a) Select c360-ml-transform Transform
2b) Select Action -> Teach transform
2c) Select I have labels and click Upload labeling file from S3
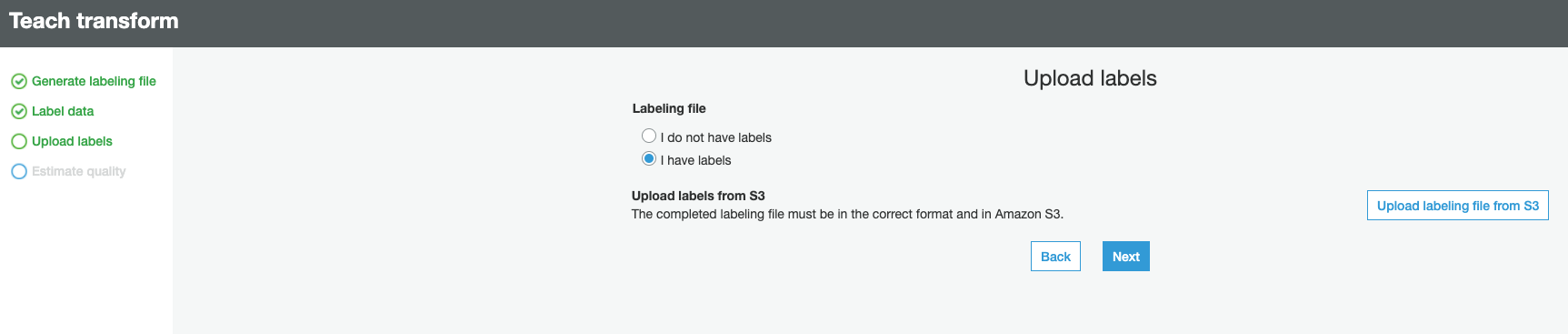
Note: Two labeled files have been pre-created for this lab - We will upload these files to teach the ML transform as shown below:
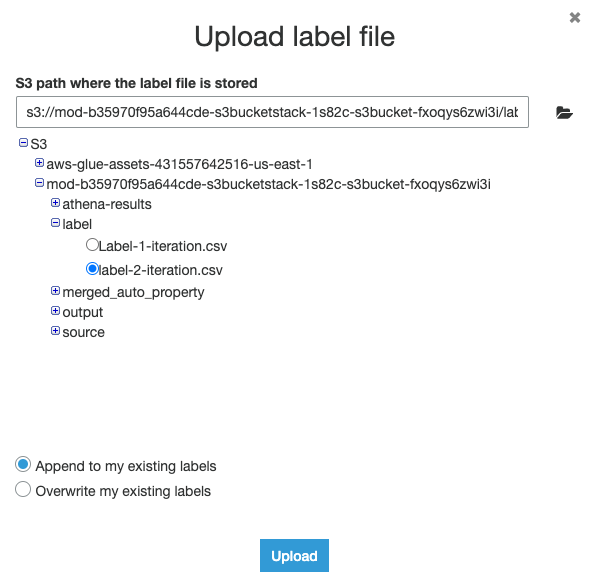
2d) Navigate to folder label in your S3 bucket, select labeled file (Label-1-iteration.csv), and click Upload
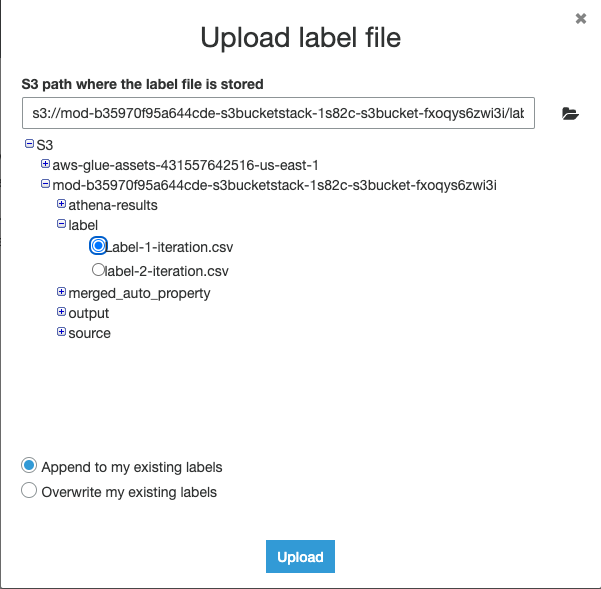
The labeled file will start uploading automatically and upload status is reported:
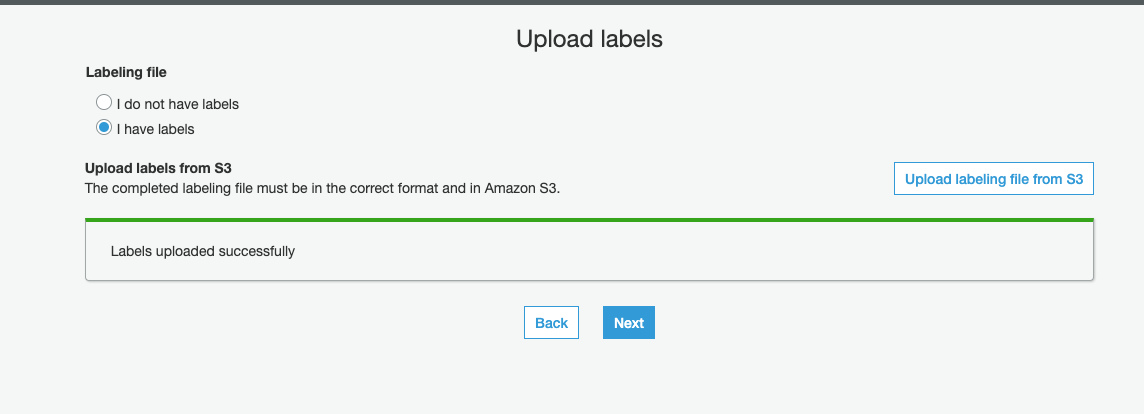
2e) Next you are taken to Estimate quality metrics (optional) page - This step provides an opportunity to estimate quality metrics at each iteration of uploading labeled files - Click Finish to skip this step
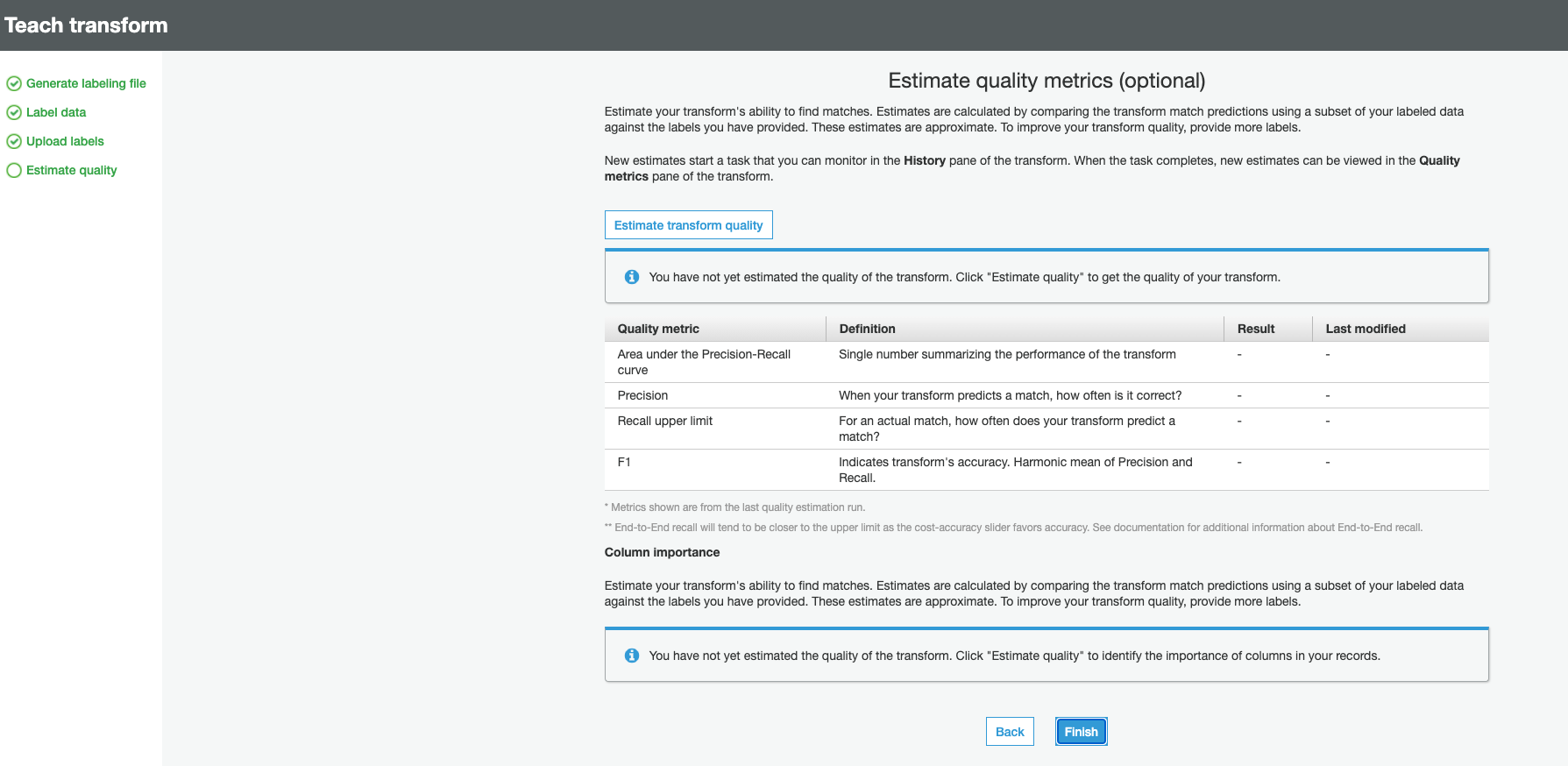
2f) Upload the second labeled file by repeating 2c) and subsequent steps for label-2-iteration.csv
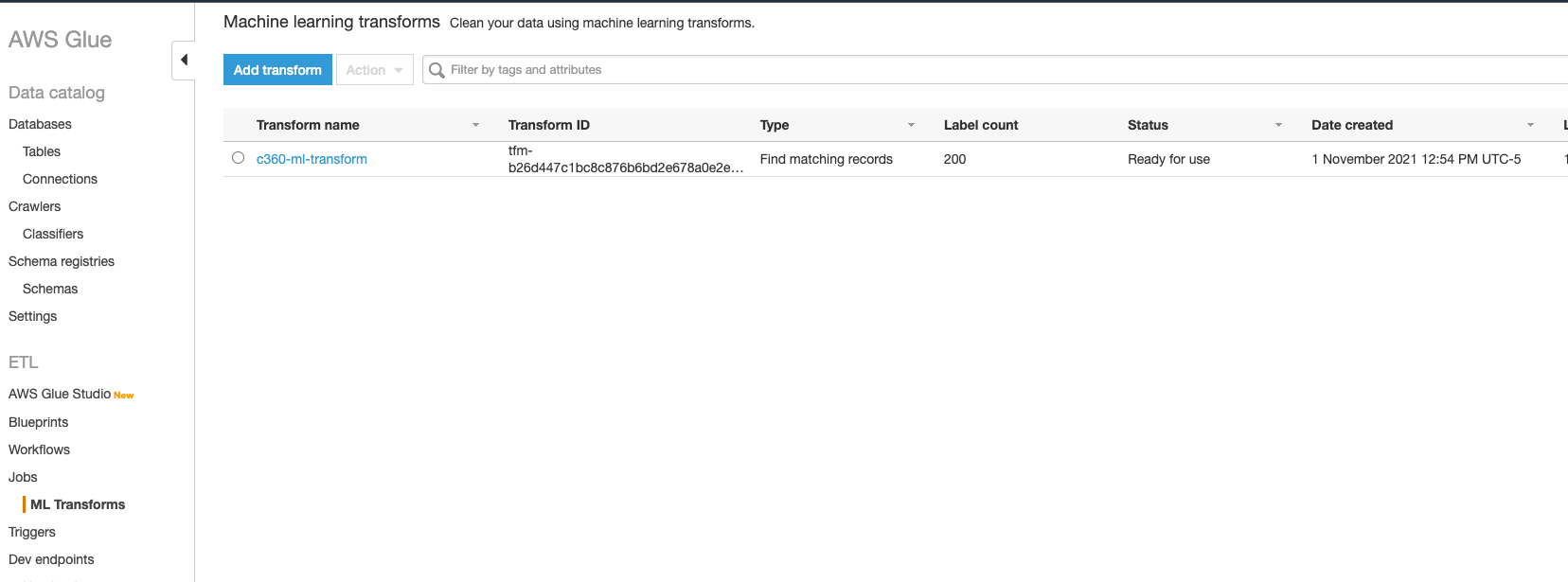
2g) Verify that the ML Transform Status is Ready for use - Note that Label Count is 200 because we successfully uploaded two labelled files to teach the transform - Now it can be used in a Glue ETL job for fuzzy matching of full dataset
3. Tune the Transform (Optional)
This completes preparation of ML Transform. Go to Create and Run ETL Job with ML Transform
APPENDIX - Steps to Generate a label file and prepare it for ML Transform