Create Glue Crawler to build the Data catalog
AWS Glue Crawler An AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of your data and other statistics, and then populates the Glue Data Catalog with this metadata
AWS Glue Data catalog The AWS Glue Data Catalog is a central repository to store structural and operational metadata for all your data assets. For a given data set, you can store its table definition, physical location, add business relevant attributes, as well as track how this data has changed over time.
In this lab, you’ll learn how to create and crawl the data in S3 source and catalog them in AWS data catalog :-
Lab Overview
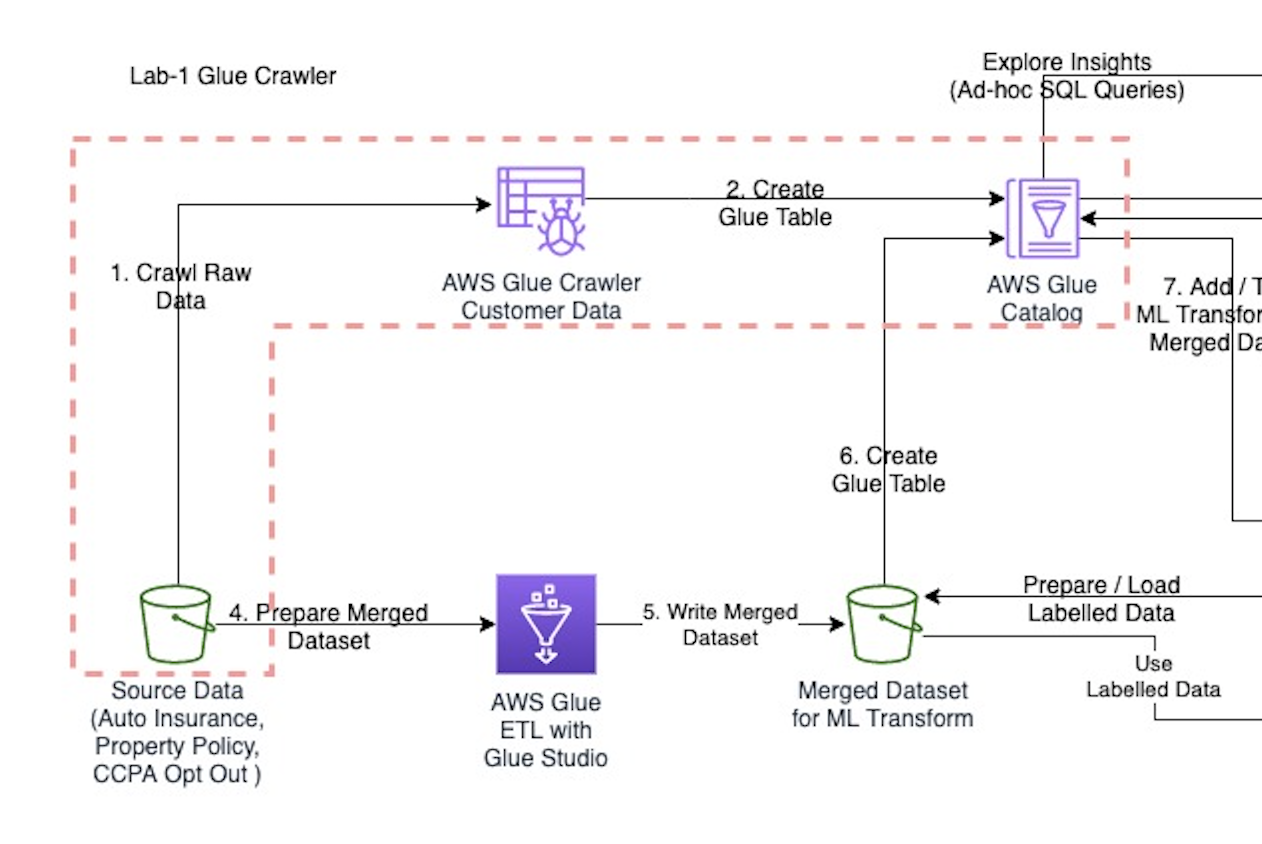
This lab is for Data steward, Data engineer and Database administrators who are getting started with AWS Glue crawler and catalog the data from different source.