Lab3 - Harmonize Customer Data with AWS Glue
Prerequisites : This lab requires Prerequisites and Lab 1 to be completed before you can continue.
In this exercise we will go through the various steps to apply machine-learning based fuzzy matching to deduplicate or harmonize customer data across auto and property insurance datasets. This is a common problem for entity records stored in multiple, disparate data sources with their own lineage that appear similar and semantically represent the same entity but do not have matching keys (or keys that work consistently) for deterministic, rule-based matching. Despite these challenges, it is critical to address this problem for creating a unified customer 360 view for driving outstanding customer experience across all channels that customer uses to interact with the business (for example, web, mobile, IVR, email, etc).
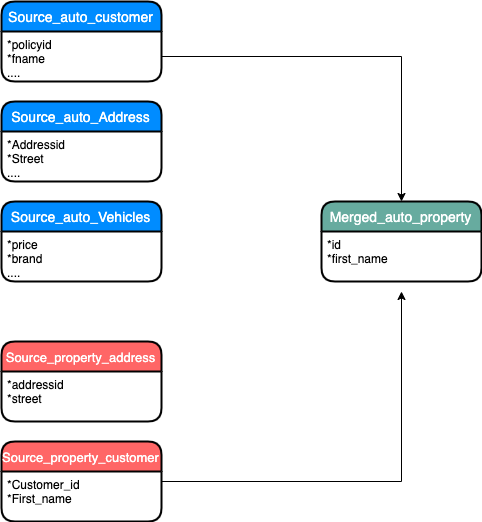
We will first use AWS Glue Studio to transform auto and property customer source data and create merged_auto_property customer dataset containing fields common to both datasets (identifiers) that a human expert (data steward) would use to determine semantic matches.
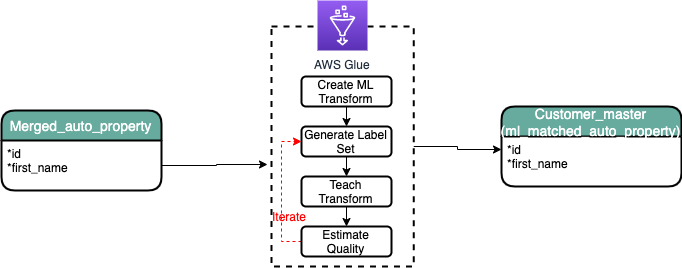
The merged_auto_property dataset is then used to de-duplicate customer records using Glue ML Transform.
This Lab contains two parts.
Part 1 :- Merging Source Auto customer table with Property customer Table ( Lab 3a ).
Part 2 :- Running Glue ML deduplication on the merged data set ( Lab 3b ).