3b - Fuzzy matching with Glue ML Transform
Prerequisites : This lab requires Lab3a to be completed before you can continue.
In this lab, we will perform fuzzy matching or de-duplication using Glue ML Transform.
Background
In today’s digital world, data is generated by large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and leveraging it to provide outstanding customer experience.
Typically, companies ingest data from multiple sources into their data lake to derive valuable insights from the data. This data often has the same meaning but uses different labels/names, which can take months to cleanse, slowing down the data processing and analytics cycle. This problem particularly impacts companies trying to build accurate, unified customer 360 profiles from customer data arriving from multiple sources. There are customer records in this data that are semantic duplicates, that is, represent the same user entity, but have different labels/values. It is commonly referred to as data harmonization or deduplication problem. The underlying schemas were implemented independently and do not adhere to common keys that can be used for joins to deduplicate records using deterministic techniques. This has led to so-called “fuzzy” deduplication techniques to address the problem. These techniques utilize various machine learning (ML) based approaches.
AWS Glue ML Transform AWS Glue provides a custom transform called FindMatches to cleanse your data using machine learning. The FindMatches transform enables you to identify duplicates or matching records in your dataset, even when the records do not have a common identifier and no fields match exactly. FindMatches makes it easy to apply machine learning (ML) - without writing any code or deep knowledge of how various ML models works.
FindMatches can be useful for addressing many different problems, such as:
Matching Customers - Linking customer records across different customer databases, even when many customer fields do not match exactly (for example, different name spellings, address differences, missing or inaccurate data, etc)
Matching Products - Matching products in your catalog against other product sources, such as product catalog against a competitor’s catalog, where entries are structured differently
Improving Fraud Detection - Identifying duplicate customer accounts, determining when a newly created account is (or might be) a match for a previously known fraudulent user
Other Matching Problems - Match addresses, movies, parts lists, etc. In general, if a human being could look at your database rows and determine that they were a match, there is a really good chance that the FindMatches transform can help you
Lab Data Set
We have used a synthetic dataset representing insurance industry. The dataset is generated using Python Faker Package, along with additional steps implemented to mimic real-life insurance customer data sets that lead to duplicates. For the sake of simplicity, we start with dataset available in Amazon S3 bucket and catalogued in AWS Glue Data Catalog in the previous lab.
Architecture
Below is the architecture flow that you will be implementing in this lab. We will focus on the highlighted portion “Customer Data Harmonization with Glue ML”. The “merged_auto_property” customer dataset prepared using Glue Studio is a required input for this Lab.
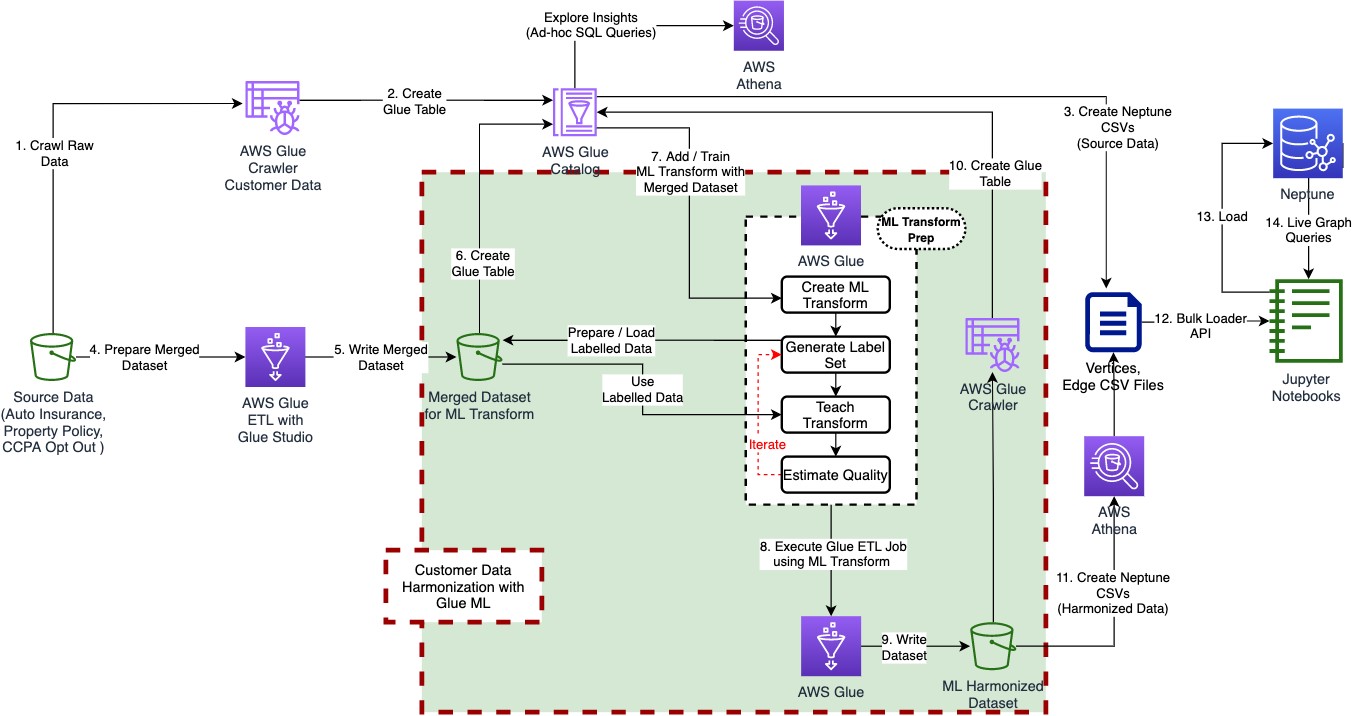
Activities
You will be performing following activities in this Lab:
1. Observe data patterns and duplicates in source data
2. Create, Teach, and Tune an AWS Glue ML Transform
3. Create and Run Glue ETL Job with ML Transform
4. Catalog de-duplicated data and explore using Athena